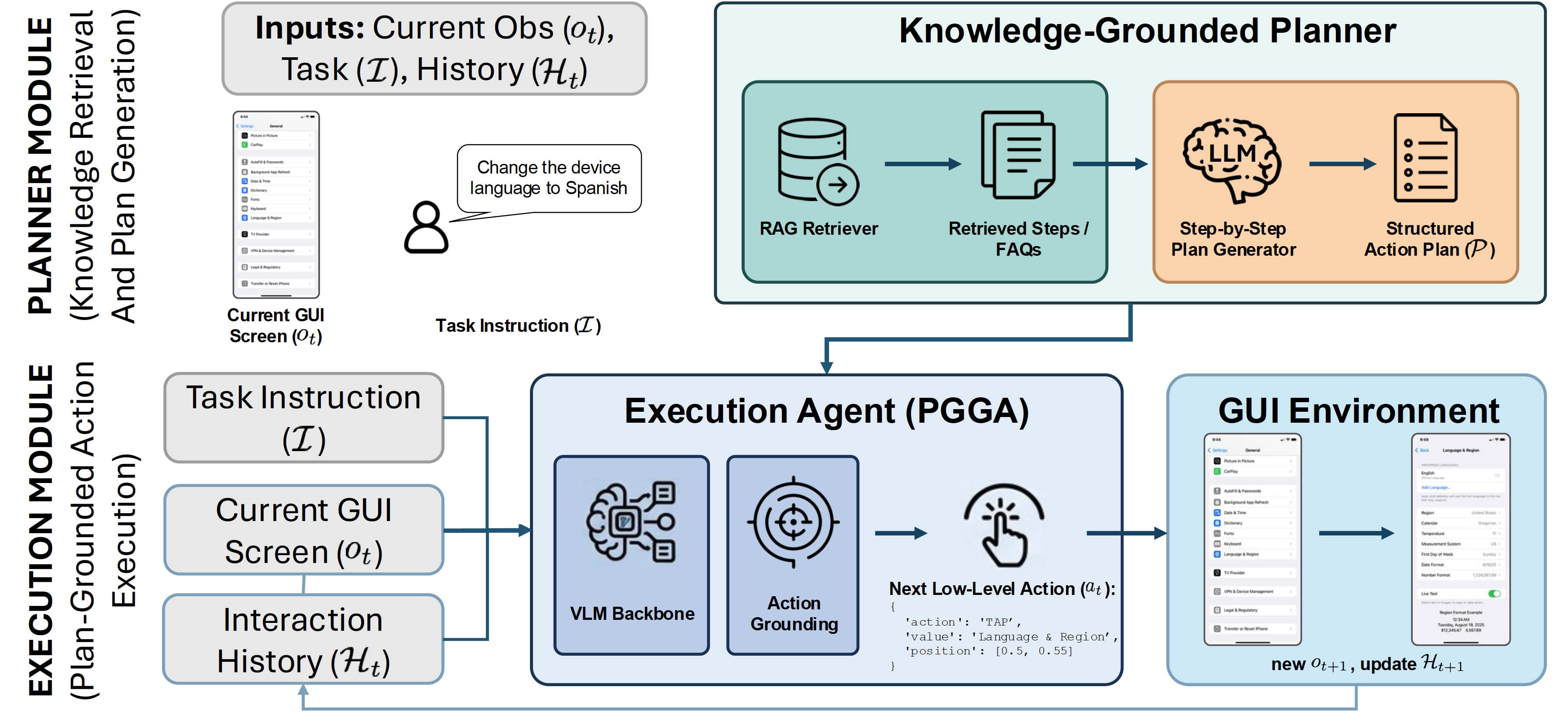
Figure 1: PGGA Framework
Figure 1: PGGA Framework
Current GUI agents struggle with multi-step digital device support. We investigate whether this failure is partly caused by a procedural knowledge deficit: agents often rely on zero-shot visual exploration instead of executing verified instructions. To address this, we introduce the Plan-Grounded GUI Agent (PGGA), which frames interface navigation as a knowledge-execution problem by conditioning low-level actions on step-by-step text plans.
PGGA targets deterministic but visually demanding device-support workflows, such as changing localization settings, navigating deep system menus, or adjusting privacy, accessibility, networking, and battery configurations. Instead of asking a vision-language model to infer the entire procedure from the current screenshot, PGGA uses an intermediate planner to retrieve procedural knowledge and synthesize an action plan. The executor then predicts the next GUI action from the task, current screenshot, interaction history, and plan.
We use grounding to mean mapping a symbolic instruction or plan step, such as "tap General", to the concrete GUI element, operation, and screen coordinate required in the current visual state. In device support, the right procedure is often known in documentation, but unguided agents still fail because they must discover both the plan and the visual target at the same time.
PGGA reformulates the standard GUI policy by adding an explicit action plan \(P\) to the observation context. The plan is not treated as an executable script: at every timestep, the model must still align the current screenshot and history with the next relevant plan step, choose the correct operation, and ground it to the target UI element.
We curate the Device-Support Interaction Benchmark (DSIB), a focused dataset of 57 high-intent mobile device-support tasks with 241 individual steps collected directly on an Apple iPhone XR. DSIB averages 4.23 steps per task and requires navigation depths of 3 to 5 hierarchical menu levels.
| Benchmark Property | Value |
|---|---|
| Tasks | 57 device-support and configuration tasks |
| Steps | 241 individual GUI actions |
| Average length | 4.23 steps per task |
| Navigation depth | 3 to 5 hierarchical menu levels |
| Domains | Localization and input, customization, connectivity, privacy, accessibility, and power management |
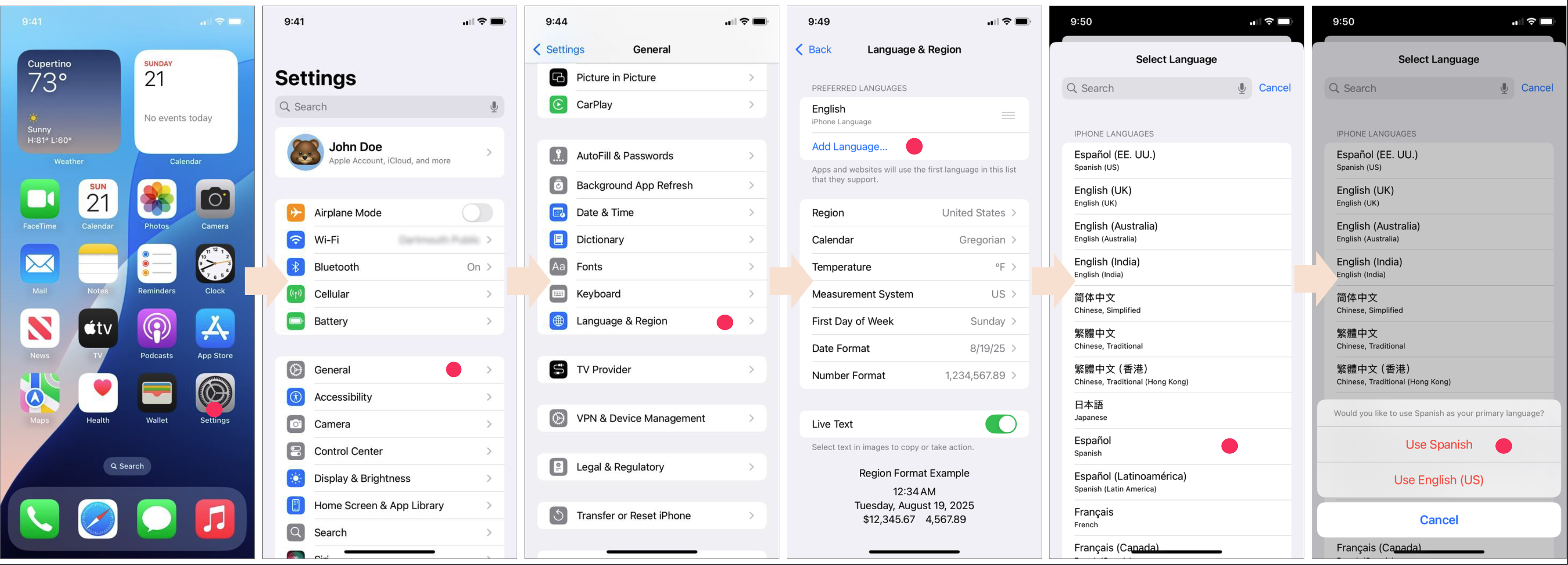
Figure 2: DSIB Example: Changing the device language to Spanish
We evaluate ShowUI-2B, GTA1-7B, and PGGA-2B across three instruction formats: task only, task plus a retrieved action plan, and task plus an expert-annotated action plan. Metrics decouple full trajectory success from visual grounding and operation prediction.
| Instruction Format | Model | Task SR | Elem. Acc. | Op. Acc. | Step SR |
|---|---|---|---|---|---|
| Task Only | ShowUI-2B | 1.75% | 46.47% | 65.97% | 35.27% |
| Task Only | GTA1-7B | 0.00% | 40.66% | 98.76% | 40.66% |
| Task Only | PGGA-2B | 7.02% | 57.26% | 90.87% | 51.45% |
| Task + Retrieved Plan | ShowUI-2B | 3.51% | 46.47% | 70.95% | 40.25% |
| Task + Retrieved Plan | GTA1-7B | 29.82% | 65.15% | 97.10% | 65.15% |
| Task + Retrieved Plan | PGGA-2B | 19.30% | 76.76% | 87.55% | 68.05% |
| Task + Expert Plan | ShowUI-2B | 3.51% | 50.21% | 88.38% | 48.96% |
| Task + Expert Plan | GTA1-7B | 45.61% | 82.99% | 99.59% | 82.57% |
| Task + Expert Plan | PGGA-2B | 54.39% | 91.28% | 95.02% | 88.38% |
Procedural knowledge is the bottleneck. Without plans, all models struggle to complete DSIB trajectories, and GTA1-7B reaches 0.00% Task Success Rate despite strong operation prediction. With expert plans, PGGA-2B rises to 54.39% Task Success Rate and 91.28% Element Accuracy.
Compact plan-conditioned execution works. PGGA-2B, a fine-tuned 2B-parameter executor, outperforms the larger GTA1-7B baseline in element accuracy and step success when provided with structured plans. This suggests that task-format adaptation and procedural conditioning can matter more than scale alone for dense GUI grounding.
Retrieval remains the gap. PGGA-2B drops from 54.39% Task Success Rate with expert plans to 19.30% with retrieved plans. Retrieved plans still improve performance, but noisy or incomplete procedural context can derail full trajectories even when individual steps are grounded accurately.
PGGA reframes automated device support from zero-shot visual exploration to grounded procedural execution. The results show that high-quality plans can substantially improve GUI execution, while future progress depends on stronger retrieval, better recovery from plan noise, and more robust long-horizon grounding.
If you find our work helpful or inspiring to your research, please cite our paper as follows:
@inproceedings{
hsiung2026pgga,
title={{PGGA}: A Plan-Grounded {GUI} Agent for Automated Device Support},
author={Lei Hsiung and Zhiyu Chen and Seonhoon Kim and Qun Liu},
booktitle={4th Workshop on Advances in Language and Vision Research (ALVR)},
year={2026},
url={https://openreview.net/forum?id=Q6us6Y1Wir}
}